Low Latency Live Stream
The RTMP and HLS can cover all requires for internet live stream, read DeliveryHLS, while RTMP is designed for low latency live stream.
The deploy for low latency, read Usage: Realtime
Use Scenario
The low latency use scenario:
- Live show.
- Video meeting.
- Other, for example, monitor, education.
Latency
RTMP is design for low latency:
- Adobe flash player is good at play RTMP stream.
- RTMP is stable enough for longtime publish and play on PC.
- Low latency, about 0.8-3s.
- For RTMP is base on TCP, the latency maybe very large for network issue.
HLS LowLatency
HLS has a bigger delay than RTMP, usually more than 5 seconds. If not set up properly, it can be over 15 seconds.
If you want to reduce the HLS delay, please check out HLS LowLatency.
Benchmark
We use the clock of mobile phone to test the latency, read RTMP latency benchmark
When netowork is ok:
- RTMP can ensure 0.8-3s latency.
- The RTMP cluster add 0.3s latency for each level.
- The latency of nginx-rtmp is larger than SRS, maybe the cache or multiple process issue.
- The gop cache always make the latency larger, but SRS can disable the gop cache.
- The bufferTime of flash client should set to small, see NetStream.bufferTime.
Min-Latency
When min-latency is enabled, SRS will diable the mr(merged-read) and use timeout cond wait, to send about 1-2 video packets when got it.
We can got 0.1s latency for vp6 video only stream, read #257. The config:
vhost mrw.srs.com {
# whether enable min delay mode for vhost.
# for min latence mode:
# 1. disable the publish.mr for vhost.
# 2. use timeout for cond wait for consumer queue.
# @see https://github.com/ossrs/srs/issues/257
# default: off
min_latency off;
}
For example to deploy realtime stream, read [wiki](EN, CN).
Merged-Read
The perfromance of RTMP read is very low, because we must read 1byte chunk type, then chunk header, finally payload. So SRS 1.0 only supports 1000 publisher, and 2700 player. SRS 2.0 supports 4500 publisher, and 10000 player.
To improve the read performance, SRS2.0 introduced the merged-read, which read Nms packets from socket then parsed in buffer. The config:
# the MR(merged-read) setting for publisher.
vhost mrw.srs.com {
# the config for FMLE/Flash publisher, which push RTMP to SRS.
publish {
# about MR, read https://github.com/ossrs/srs/issues/241
# when enabled the mr, SRS will read as large as possible.
# default: off
mr off;
# the latency in ms for MR(merged-read),
# the performance+ when latency+, and memory+,
# memory(buffer) = latency * kbps / 8
# for example, latency=500ms, kbps=3000kbps, each publish connection will consume
# memory = 500 * 3000 / 8 = 187500B = 183KB
# when there are 2500 publisher, the total memory of SRS atleast:
# 183KB * 2500 = 446MB
# the value recomment is [300, 2000]
# default: 350
mr_latency 350;
}
}
That is, when merged-read enabled, the read buffer of SRS is latency ms, the latency also increase to this value.
For low latency, user should disable merged-read, SRS will recv and parse the packet immediately.
Merged-Write
SRS always use merged-write to send packets. This algorithm can improve about 500% performance, for example, SRS 1.0 writev a packet which supports 2700 clients, while SRS 2.0 writev multiple packets and supports 10000 clients.
User can config the merged write pacets in ms, recomment to use default value:
# the MW(merged-write) settings for player.
vhost mrw.srs.com {
# for play client, both RTMP and other stream clients,
# for instance, the HTTP FLV stream clients.
play {
# set the MW(merged-write) latency in ms.
# SRS always set mw on, so we just set the latency value.
# the latency of stream >= mw_latency + mr_latency
# the value recomment is [300, 1800]
# default: 350
mw_latency 350;
}
}
User can config this to 100ms for very low latency.
GOP-Cache
The gop is the gop between two I frame.
SRS use gop-cache to cache the last gop for the live stream, when client play stream, SRS can send the last gop to client to enable the client to start play immediately.
Config of srs:
# the listen ports, split by space.
listen 1935;
vhost __defaultVhost__ {
# for play client, both RTMP and other stream clients,
# for instance, the HTTP FLV stream clients.
play {
# whether cache the last gop.
# if on, cache the last gop and dispatch to client,
# to enabled fast startup for client, client play immediately.
# if off, send the latest media data to client,
# client need to wait for the next Iframe to decode and show the video.
# set to off if requires min delay;
# set to on if requires client fast startup.
# default: on
gop_cache off;
}
}
Read about the min.delay.com in conf/full.conf.
Low Latency config
Recoment to use the bellow config for low latency application:
# the listen ports, split by space.
listen 1935;
vhost __defaultVhost__ {
tcp_nodelay on;
min_latency on;
play {
gop_cache off;
queue_length 10;
mw_latency 100;
}
publish {
mr off;
}
}
Benchmark Data
SRS: 0.9.55
Encoder: FMLE, video(h264, profile=baseline, level=3.1, keyframe-frequency=5seconds), fps=15, input=640x480, output(500kbps, 640x480), no audio output.
Network: Publish to aliyun qindao server.
SRS config:
listen 1935;
vhost __defaultVhost__ {
enabled on;
play {
gop_cache off;
}
hls {
enabled on;
hls_path ./objs/nginx/html;
hls_fragment 5;
hls_window 20;
}
}
Latency: RTMP 2s, HLS 24s.
Read: 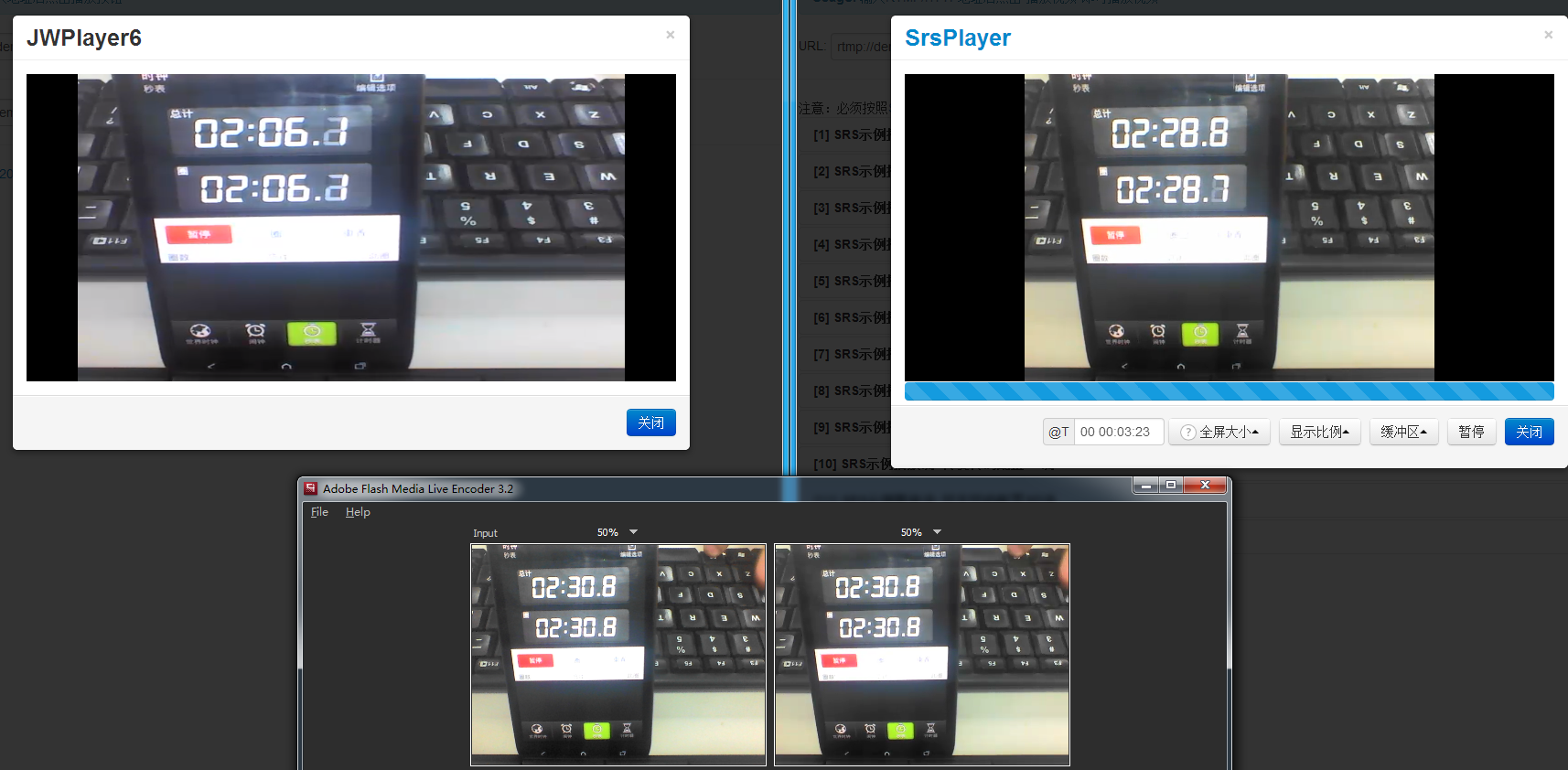
Edge Benchmark Data
SRS RTMP cluster almost not add more latency.
Read 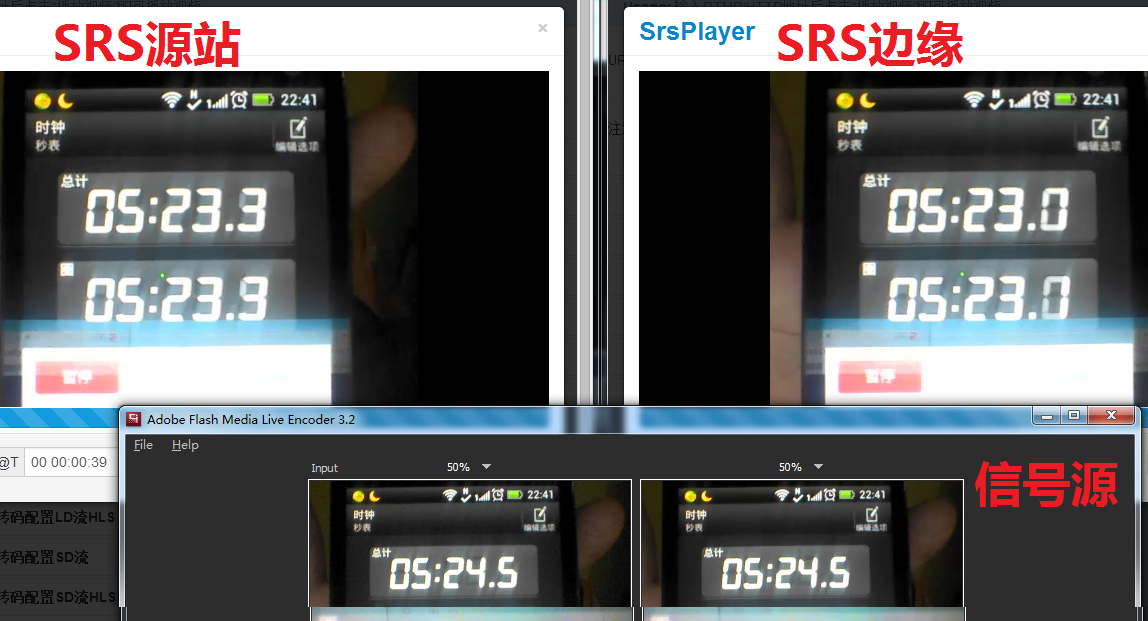
Winlin 2015.8
